Sorting Records in Representations of Product Composition |
  
|
Sorting Records in Representations of Product Composition |
|
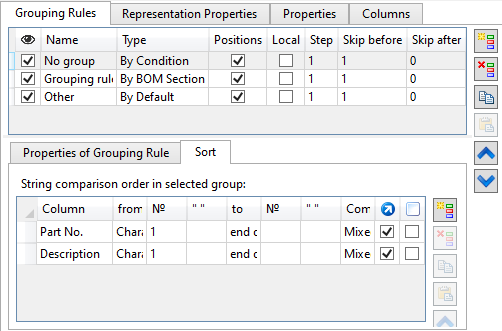
The Sorting tab allows to customize order of records within the resulting group.
The tab contains list of sorting rules for the group created by the grouping rule selected in the list above.
If sorting rules for the group are not set, the records of the product composition will be placed in an arbitrary order.
Important! The order of applying sorting rules depends on their order in the list.
Sorting rules can be selected in the list using ![]() .
.
To the right of the sorting list there are buttons of following commands:
![]() Add <Ctrl>+<N>
Add <Ctrl>+<N>
Adds a new rule to the bottom of the list.
![]() Delete <Del>
Delete <Del>
Deletes selected rule.
![]() Copy <Ctrl>+<C>
Copy <Ctrl>+<C>
Copies selected rule into clipboard.
![]() Paste <Ctrl>+<V>
Paste <Ctrl>+<V>
Pastes a rule from clipboard.
![]() Up and
Up and ![]() Down
Down
Move selected rule up or down the list.
Following parameters are displayed in the list for each sorting rule:
Column
The data will be sorted by the column selected in this drop-down list.
From
The start of the comparison region. One of the following options can be selected in the drop-down list:
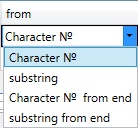
•Character № -
The comparison region will start at a symbol, whose position from the start of a compared string is specified in the № box. For example, №=3 means, that the comparison region starts at the third character from the start of the string. If a compared string contains less symbols, than the specified number, then such string is considered empty.
•substring
The comparison region will start at a sequence of symbols specified in the " " box. Index number of the sequence from the start of a compared string is set in the № box. By default, №=1, so the comparison region starts at the first occurrence of the specified sequence within a compared string. If a compared string doesn't contain the specified sequence, or the number of sequence's occurrences within the string is lower than the specified index number, then the string is considered empty.
•Character № from end
The comparison region will start at a symbol, whose position from the end of a compared string is specified in the № box. For example, №=3 means, that the comparison region starts at the third character from the end of the string. If a compared string contains less symbols, than the specified number, then such string is considered empty.
•substring from end
The comparison region will start at a sequence of symbols specified in the " " box. Index number of the sequence from the end of a compared string is set in the № box. By default, №=1, so the comparison region starts at the last occurrence of the specified sequence within a compared string. If a compared string doesn't contain the specified sequence, or the number of sequence's occurrences within the string is lower than the specified index number, then the string is considered empty.
To
The end of the comparison region. One of the following options can be selected in the drop-down list:
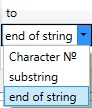
•character №
The comparison region will end at a symbol, whose position from the start of a compared string is specified in the № box. For example, №=10 means, that the comparison region ends at the tenth character from the start of the string. If a compared string contains less symbols, than the specified number, then the comparison region ends at the end of the string.
•substring
The comparison region will end at a sequence of symbols specified in the " " box. Index number of the sequence from the start of a compared string is set in the № box. By default, №=1, so the comparison region ends at the first occurrence of the specified sequence within a compared string. If a compared string doesn't contain the specified sequence, or the number of sequence's occurrences within the string is lower than the specified index number, then the comparison region ends at the end of the string.
•end of string
The comparison region ends at the end of the string.
№
The index number of a character or substring within a string is typed into these boxes. One box defines the start of the comparison region (From), another one - the end (To).
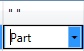
“ ”
The substring is typed into these boxes, if the substring or substring from end option is selected for From and/or To parameters. One box defines the start of the comparison region (From), another one - the end (To).
Compare
The method of comparing data. One of the following options can be selected in the drop-down list:
•Character
Content of two data cells of the table will be compared as two textual strings.
•Numeric
Content of two data cells of the table will be compared as two numeric values. If a value in a cell doesn't start with a digit, such cell is considered empty. If a value in a cell starts with digits followed by non-numeric characters, then all characters, except the first sequence of digits, will be omitted on comparison.
•Mixed
A string will be divided into substrings, where each substring contains either textual or numeric value. After that, same-type substrings will be compared. A single dot or a comma between digits is considered a splitter between two numeric substrings. Type of splitter affects sorting - comma has a priority over dot. If a content of the of the first cell starts with a digit, the system selects a numeric substring from the start of the cell and compares its value with a numeric substring found in the second cell. If a value of the second cell doesn't start with a digit, then the substring from the first cell is compared with an empty numerical substring. Then, a substring containing non-numeric characters is allocated in the first cell, and the characters are compared in both cells, starting from the position following the last digit of the substring used in the previous comparison step. Thus, the contents of both cells are analyzed until the end of the first cell. When same position is occupied by a digit in one cell, and by a textual symbol in another cell, then the digit has a priority. If textual substrings contains same characters, but have different length (like "AA" and "AAA"), then the shorter string has a priority.
•Mixed Universal
This method works in the same way as Mixed. The only difference is that type of splitter between numeric substrings doesn't affect sorting.
•Mixed Numeric
This method works in the same way as Mixed Universal. The only difference is that the first single dot found after beginning of a numeric substring is considered a decimal symbol.
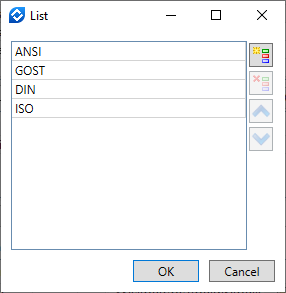
•By List
Upon selecting this method, all you have to specify is a Column and a list of values for its sorting. In order to specify a list of values, first click ![]() a row of a sorting rule. The row will get highlighted. Then click
a row of a sorting rule. The row will get highlighted. Then click ![]() a cell of this row in the left " " column of the sorting rules list. The
a cell of this row in the left " " column of the sorting rules list. The ![]() List button will appear in the cell. This button opens the List dialog.
List button will appear in the cell. This button opens the List dialog.

The List dialog contains the list of textual substrings. Product composition records in the current group containing the listed substrings will be sorted in the order of substrings in the list. Other records will be put to the end of the group. Substrings in the list can be selected using ![]() . Selected substring gets highlighted. You can
. Selected substring gets highlighted. You can ![]() Add <Ctrl>+<N> a new substring after the selected one,
Add <Ctrl>+<N> a new substring after the selected one, ![]() Delete <Del> the selected substring or move it
Delete <Del> the selected substring or move it ![]() Up or
Up or ![]() Down the list using buttons located in the right section of the dialog. Double click
Down the list using buttons located in the right section of the dialog. Double click ![]()
![]() a substring to type in its content.
a substring to type in its content.
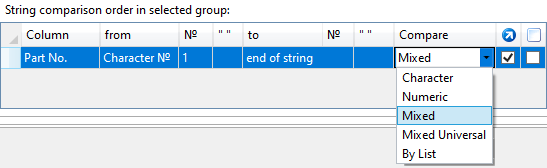
Example of sorting creation
Sorting will be set for the Part No. column for all records in the Grouping rule_1 section.

Each data cell of Part No. column will be searched for the first “Part” substring from the beginning.
Searching is performed to the end of string. Type of comparison is set to Mixed, i.e. all characters and numbers after the specified substring will be taken into account.
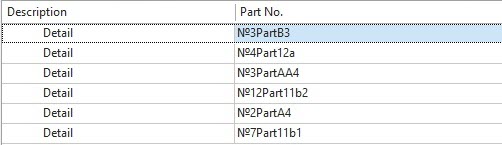
The order of records before sorting is shown below:
Upon ![]() applying the representation with sorting, records are sorted as follows:
applying the representation with sorting, records are sorted as follows:
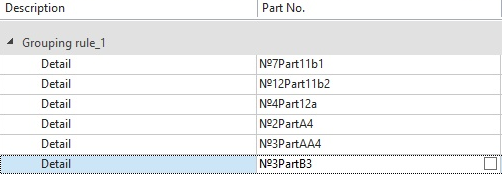
The characters and numbers before Part substring were not taken into account.
Initially the comparison was made by the first position after the Part substring.
Digits on the first position were selected from each cell (1). They were combined into numbers with adjacent digits (11, 12). After that, they were compared.
Then all non-numeric characters on the first position were selected (A, B). They were combined into substrings with adjacent non-numeric characters, if available (AA). They were compared.
Then symbols on the second position were compared and so on until the end of the string.